Problems we faced and the potential solution
Mapping foreign key
Cassandra does not support the concept of foreign keys and RDBMS store data in a related manner. This was the biggest problem we faced in this project as a whole. If we just leave the foreign key related data and only transfer the rest it will not make any sense. To preserve this cSiTra comes up with a novel solution.
The solution is to simulate the purpose of foreign key (not the foreign key itself) by creating a Column Family to represent each reference where the foreign key of that reference is the primary key in the created Column Family and all related primary key in the original reference table will be inserted as columns in this Column Family.
Mismatch-in-conventions
Another problem was which occurred during the implementation was that some datatype values are represented in different ways in different SQL databases. For example the Boolean type in some databases is represented as (1, 0), in another (true, false) and some other database used the first letter (t,f). So we had to check the value of the datatype and then actually convert it into Cassandra equivalents (in the example Boolean case its (true, false)).
Data referencing
While implementing cSiTra we faced a problem with referencing three key items of Cassandra, the column families, Primary keys and column combination. According to the Cassandra meta-model we designed, if we have a column that is said to be part of primary key in a column family then we need to add this column object to both columns field in column family & to that of the primary key objects. The problem we faced was that if such a column object was added to both primary key object and column family object, the reference to this column object would be deleted from either the primary key object or Column Family object depending on the order in which we were trying to add the column object.
The reason for this problem is that we used containment relations for both of the columns and the primary key related to the column family. And a possible solution is to change the relations.
Data Transfer
We faced a performance problem with large amount of data. If the table contains more than 150,000 record, the time to read and transfer the data threw SiTra will start to increase exponentially. This happened because of using lists and objects in reading and transferring the schema and the data.
Proposed solutions:
- Transfer the structure (schema) only using SiTra and find another way to transfer the data, like use two processes one to read from SQL database and write into a file and another one will read from the file into Cassandra database. When the first process is done from writing it will terminate itself. For the second process we will have a timer to set a timeout to terminate if the process remained ideal for a certain amount of time.
- Another solution is to read the SQL schema and data into a JSON format files. Each file will represent a table with its data. The created JSON file will be passed to SiTra and the output will be another JSON file but with data formatted in Cassandra structure. These JSON files will be parsed and inserted to Cassandra to create the column families and insert data.
Future work
As a part of the future work, the cSiTra Team has planned the following, and also they encourage fellow developers who are interested to try them:
Enhance performance: Make cSiTra multithreaded, and try to include a producer-consumer like model for reading RDBMSs and writing the equivalents to Cassandra.
Implement proposed solution: A few problems and pitfalls have been mentioned in the problems we faced section, and these need some attention.
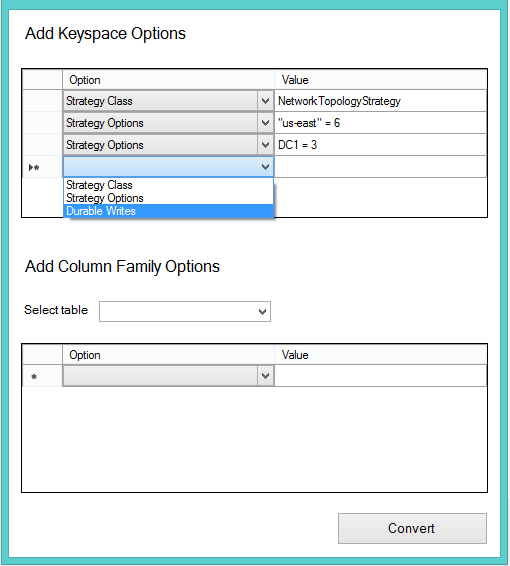
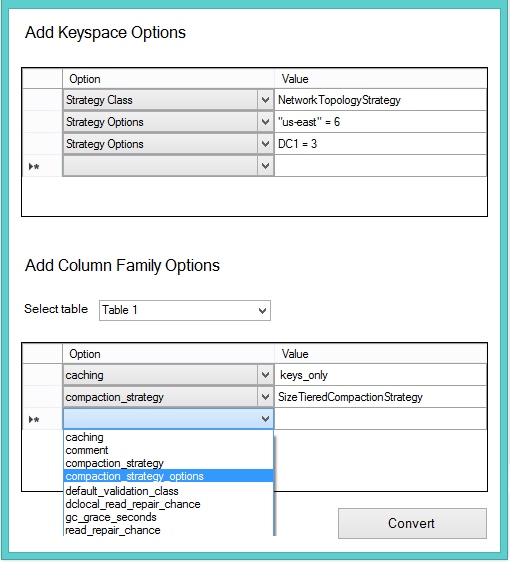
Add more functionality and UI: Make cSiTra more elegant by adding more UI elements (like the ones shown below) and also to make cSiTra more interactive and provide menus to set options for Cassandra KeySpace and column families